Scientific publication
Real-Time Monitoring and Quality Assurance for Laser-Based Directed Energy Deposition: Integrating Coaxial Imaging and Self-Supervised Deep Learning Framework
Written by Vigneashwara Pandiyan, Di Cui, Roland Axel Richter, Annapaola Parrilli and Marc Leparoux
Outline
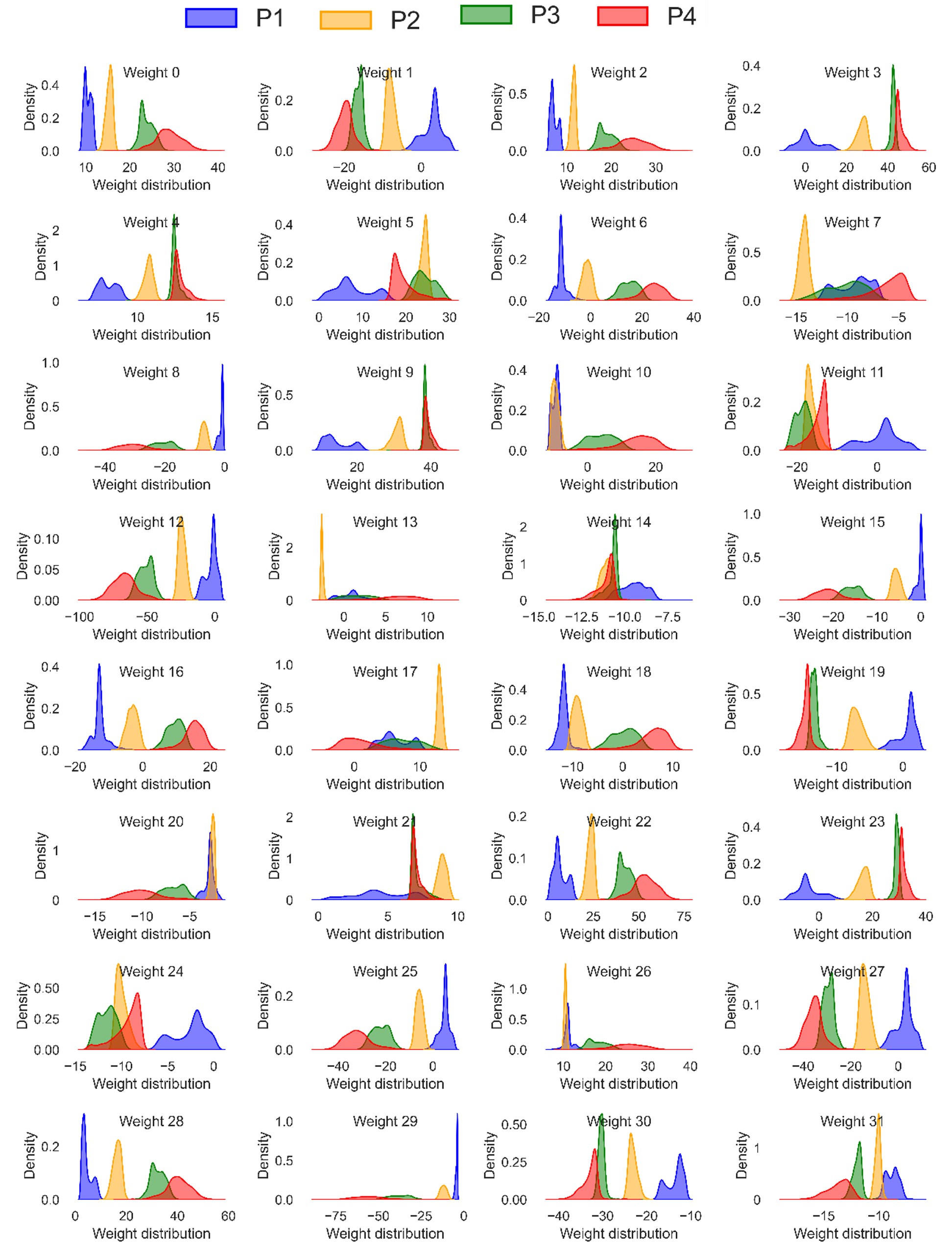
Artificial Intelligence (AI) has emerged as a promising solution for real-time monitoring of the quality of additively manufactured (AM) metallic parts. This study focuses on the Laser-based Directed Energy Deposition (LDED) process and utilizes embedded vision systems to capture critical melt pool characteristics for continuous monitoring. Two self-learning frameworks based on Convolutional Neural Networks and Transformer architecture are applied to process zone images from different DED process regimes, enabling in-situ monitoring without ground truth information. The evaluation is based on a dataset of process zone images obtained during the deposition of titanium powder (Cp-Ti, grade 1), forming a cube geometry using four laser regimes. By training and evaluating the Deep Learning (DL) algorithms using a co-axially mounted CCD camera within the process zone, the down-sampled representations of process zone images are effectively used with conventional classifiers for L-DED process monitoring. The high classification accuracies achieved validate the feasibility and efficacy of self-learning strategies in real-time quality assessment of AM. This study highlights the potential of AI-based monitoring systems and selflearning algorithms in quantifying the quality of AM metallic parts during fabrication. The integration of embedded vision systems and self-learning algorithms presents a novel contribution, particularly in the context of the L-DED process. The findings open avenues for further research and development in AM process monitoring, emphasizing the importance of self-supervised in-situ monitoring techniques in ensuring part quality during fabrication.

Reference
Pandiyan, Vigneashwara, Di Cui, Roland Axel Richter, Annapaola Parrilli, and Marc Leparoux. "Real-time monitoring and quality assurance for laser-based directed energy deposition: integrating co-axial imaging and self-supervised deep learning framework." Journal of Intelligent Manufacturing (2023): 1-25..
Graphical abstract

Bootstrap your own latent (BYOL) learners
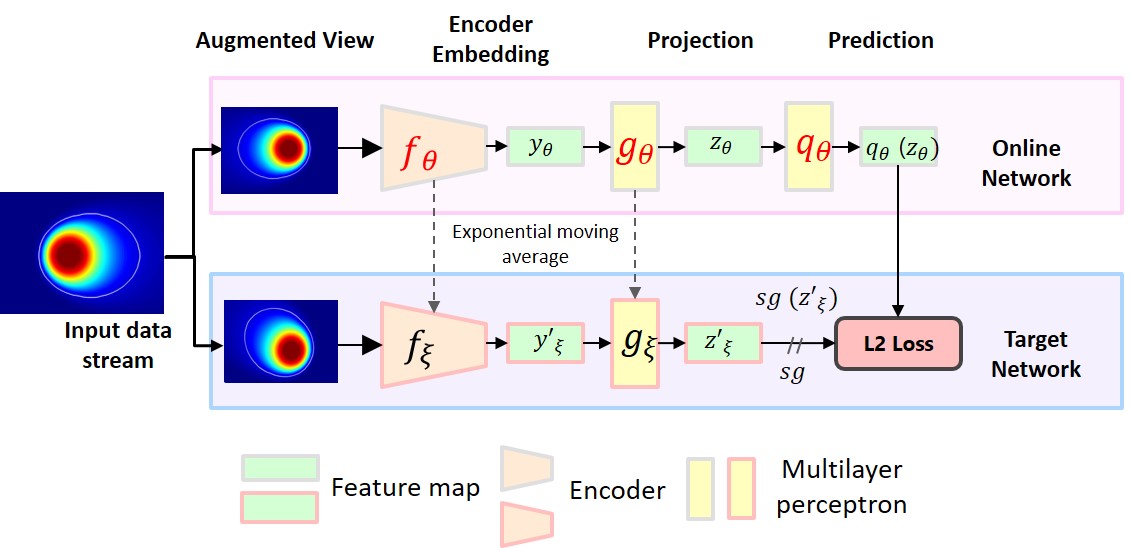

The training of ML algorithms is usually supervised. Given a dataset consisting of an input and corresponding label, under a supervised paradigm, a typical classification algorithm tries to discover the best function that maps the input data to the correct labels. On the contrary, self-supervised learning does not classify the data to its labels. Instead, it learns about functions that map input data to themselves . Self-supervised learning helps reduce the amount of labelling required. Additionally, a model self-supervisedly trained on unlabeled data can be refined on a smaller sample of annotated data. BYOL is a state-of-the-art self-supervised method proposed by researchers in DeepMind and Imperial College that can learn appropriate image representations for many downstream tasks at once and does not require labelled negatives like most contrastive learning methods. The BYOL framework consists of two neural networks, online and target, that interact and learn from each other iteratively through their bootstrap representations, as shown in Figure below. Both networks share the architectures but not the weights. The online network is defined by a set of weights θ and comprises three components: Encoder, projector, and predictor. The architecture of the target network is the same as the online network but with a different set of weights ξ, which are initialized randomly. The online network has an extra Multi-layer Perceptron (MLP) layer, making the two networks asymmetric. During training, an online network is trained from one augmented view of an image to predict a target network representation of the same image under another augmented view. The standard augmentation applied on the actual images is a random crop, jitter, rotation, translation, and others. The objective of the training was to minimize the distance between the embeddings computed from the online and target network. BYOL's popularity stems primarily from its ability to learn representations for various downstream visual computing tasks such as object recognition and semantic segmentation or any other task-specific network, as it gets a better result than training these networks from scratch. As far as this work is concerned, based on the shape of the process zone and the four quality categories that were gathered, BYOL was employed in this work to develop appropriate representations that could be used for in-situ process monitoring.

Results